5. Run the mass-balance calibration¶
Sometimes you will need to do the mass-balance calibration yourself. For example if you use alternate climate data, or if you change the global parameters of the model (such as precipitation scaling factor or melting threshold, for example). Here we show how to run the calibration for all available reference glaciers. We also use this example to illustrate how to do a “full run”, i.e. without relying on Pre-processed directories.
The output of this script is the ref_tstars.csv file, which is found in
the working directory. The ref_tstars.csv file can then be used for further
runs, simply by copying it in the corresponding working directory before the
run.
Script¶
# Python imports
import json
import os
# Libs
import numpy as np
# Locals
import oggm
from oggm import cfg, utils, tasks, workflow
from oggm.workflow import execute_entity_task
from oggm.core.massbalance import (ConstantMassBalance, PastMassBalance,
MultipleFlowlineMassBalance)
# Module logger
import logging
log = logging.getLogger(__name__)
# RGI Version
rgi_version = '61'
# CRU or HISTALP?
baseline = 'CRU'
# Initialize OGGM and set up the run parameters
cfg.initialize()
# Local paths (where to write the OGGM run output)
dirname = 'OGGM_ref_mb_{}_RGIV{}_OGGM{}'.format(baseline, rgi_version,
oggm.__version__)
WORKING_DIR = utils.gettempdir(dirname, home=True)
utils.mkdir(WORKING_DIR, reset=True)
cfg.PATHS['working_dir'] = WORKING_DIR
# We are running the calibration ourselves
cfg.PARAMS['run_mb_calibration'] = True
# We are using which baseline data?
cfg.PARAMS['baseline_climate'] = baseline
# Use multiprocessing?
cfg.PARAMS['use_multiprocessing'] = True
# Set to True for operational runs - here we want all glaciers to run
cfg.PARAMS['continue_on_error'] = False
if baseline == 'HISTALP':
# Other params: see https://oggm.org/2018/08/10/histalp-parameters/
cfg.PARAMS['baseline_y0'] = 1850
cfg.PARAMS['prcp_scaling_factor'] = 1.75
cfg.PARAMS['temp_melt'] = -1.75
# Get the reference glacier ids (they are different for each RGI version)
rgi_dir = utils.get_rgi_dir(version=rgi_version)
df, _ = utils.get_wgms_files()
rids = df['RGI{}0_ID'.format(rgi_version[0])]
# We can't do Antarctica
rids = [rid for rid in rids if not ('-19.' in rid)]
# For HISTALP only RGI reg 11
if baseline == 'HISTALP':
rids = [rid for rid in rids if '-11.' in rid]
# Make a new dataframe with those (this takes a while)
log.info('Reading the RGI shapefiles...')
rgidf = utils.get_rgi_glacier_entities(rids, version=rgi_version)
log.info('For RGIV{} we have {} candidate reference '
'glaciers.'.format(rgi_version, len(rgidf)))
# We have to check which of them actually have enough mb data.
# Let OGGM do it:
gdirs = workflow.init_glacier_regions(rgidf)
# We need to know which period we have data for
log.info('Process the climate data...')
if baseline == 'CRU':
execute_entity_task(tasks.process_cru_data, gdirs, print_log=False)
elif baseline == 'HISTALP':
cfg.PARAMS['continue_on_error'] = True # Some glaciers are not in Alps
execute_entity_task(tasks.process_histalp_data, gdirs, print_log=False)
cfg.PARAMS['continue_on_error'] = False
gdirs = utils.get_ref_mb_glaciers(gdirs)
# Keep only these
rgidf = rgidf.loc[rgidf.RGIId.isin([g.rgi_id for g in gdirs])]
# Save
log.info('For RGIV{} and {} we have {} reference glaciers.'.format(rgi_version,
baseline,
len(rgidf)))
rgidf.to_file(os.path.join(WORKING_DIR, 'mb_ref_glaciers.shp'))
# Sort for more efficient parallel computing
rgidf = rgidf.sort_values('Area', ascending=False)
# Go - initialize glacier directories
gdirs = workflow.init_glacier_regions(rgidf)
# Prepro tasks
task_list = [
tasks.glacier_masks,
tasks.compute_centerlines,
tasks.initialize_flowlines,
tasks.catchment_area,
tasks.catchment_intersections,
tasks.catchment_width_geom,
tasks.catchment_width_correction,
]
for task in task_list:
execute_entity_task(task, gdirs)
# Climate tasks
tasks.compute_ref_t_stars(gdirs)
execute_entity_task(tasks.local_t_star, gdirs)
execute_entity_task(tasks.mu_star_calibration, gdirs)
# We store the associated params
mb_calib = gdirs[0].read_pickle('climate_info')['mb_calib_params']
with open(os.path.join(WORKING_DIR, 'mb_calib_params.json'), 'w') as fp:
json.dump(mb_calib, fp)
# And also some statistics
utils.compile_glacier_statistics(gdirs)
# Tests: for all glaciers, the mass-balance around tstar and the
# bias with observation should be approx 0
for gd in gdirs:
mb_mod = MultipleFlowlineMassBalance(gd,
mb_model_class=ConstantMassBalance,
use_inversion_flowlines=True,
bias=0) # bias=0 because of calib!
mb = mb_mod.get_specific_mb()
np.testing.assert_allclose(mb, 0, atol=5) # atol for numerical errors
mb_mod = MultipleFlowlineMassBalance(gd, mb_model_class=PastMassBalance,
use_inversion_flowlines=True)
refmb = gd.get_ref_mb_data().copy()
refmb['OGGM'] = mb_mod.get_specific_mb(year=refmb.index)
np.testing.assert_allclose(refmb.OGGM.mean(), refmb.ANNUAL_BALANCE.mean(),
atol=5) # atol for numerical errors
# Log
log.info('Calibration is done!')
Cross-validation¶
The results of the cross-validation are found in the crossval_tstars.csv
file. Let’s replicate Figure 3 in Marzeion et al., (2012) :
# Python imports
import os
# Libs
import numpy as np
import pandas as pd
import geopandas as gpd
# Locals
import oggm
from oggm import cfg, workflow, tasks, utils
from oggm.core.massbalance import PastMassBalance, MultipleFlowlineMassBalance
import matplotlib.pyplot as plt
# RGI Version
rgi_version = '61'
# CRU or HISTALP?
baseline = 'CRU'
# Initialize OGGM and set up the run parameters
cfg.initialize()
if baseline == 'HISTALP':
# Other params: see https://oggm.org/2018/08/10/histalp-parameters/
cfg.PARAMS['prcp_scaling_factor'] = 1.75
cfg.PARAMS['temp_melt'] = -1.75
# Local paths (where to find the OGGM run output)
dirname = 'OGGM_ref_mb_{}_RGIV{}_OGGM{}'.format(baseline, rgi_version,
oggm.__version__)
WORKING_DIR = utils.gettempdir(dirname, home=True)
cfg.PATHS['working_dir'] = WORKING_DIR
# Read the rgi file
rgidf = gpd.read_file(os.path.join(WORKING_DIR, 'mb_ref_glaciers.shp'))
# Go - initialize glacier directories
gdirs = workflow.init_glacier_regions(rgidf)
# Cross-validation
file = os.path.join(cfg.PATHS['working_dir'], 'ref_tstars.csv')
ref_df = pd.read_csv(file, index_col=0)
for i, gdir in enumerate(gdirs):
print('Cross-validation iteration {} of {}'.format(i + 1, len(ref_df)))
# Now recalibrate the model blindly
tmp_ref_df = ref_df.loc[ref_df.index != gdir.rgi_id]
tasks.local_t_star(gdir, ref_df=tmp_ref_df)
tasks.mu_star_calibration(gdir)
# Mass-balance model with cross-validated parameters instead
mb_mod = MultipleFlowlineMassBalance(gdir, mb_model_class=PastMassBalance,
use_inversion_flowlines=True)
# Mass-balance timeseries, observed and simulated
refmb = gdir.get_ref_mb_data().copy()
refmb['OGGM'] = mb_mod.get_specific_mb(year=refmb.index)
# Compare their standard deviation
std_ref = refmb.ANNUAL_BALANCE.std()
rcor = np.corrcoef(refmb.OGGM, refmb.ANNUAL_BALANCE)[0, 1]
if std_ref == 0:
# I think that such a thing happens with some geodetic values
std_ref = refmb.OGGM.std()
rcor = 1
# Store the scores
ref_df.loc[gdir.rgi_id, 'CV_MB_BIAS'] = (refmb.OGGM.mean() -
refmb.ANNUAL_BALANCE.mean())
ref_df.loc[gdir.rgi_id, 'CV_MB_SIGMA_BIAS'] = (refmb.OGGM.std() / std_ref)
ref_df.loc[gdir.rgi_id, 'CV_MB_COR'] = rcor
# Write out
ref_df.to_csv(os.path.join(cfg.PATHS['working_dir'], 'crossval_tstars.csv'))
# Marzeion et al Figure 3
f, ax = plt.subplots(1, 1)
bins = np.arange(20) * 400 - 3800
ref_df['CV_MB_BIAS'].plot(ax=ax, kind='hist', bins=bins, color='C3', label='')
ax.vlines(ref_df['CV_MB_BIAS'].mean(), 0, 120, linestyles='--', label='Mean')
ax.vlines(ref_df['CV_MB_BIAS'].quantile(), 0, 120, label='Median')
ax.vlines(ref_df['CV_MB_BIAS'].quantile([0.05, 0.95]), 0, 120, color='grey',
label='5% and 95%\npercentiles')
ax.text(0.01, 0.99, 'N = {}'.format(len(gdirs)),
horizontalalignment='left',
verticalalignment='top',
transform=ax.transAxes)
ax.set_ylim(0, 120)
ax.set_ylabel('N Glaciers')
ax.set_xlabel('Mass-balance error (mm w.e. yr$^{-1}$)')
ax.legend(loc='best')
plt.tight_layout()
plt.show()
scores = 'Median bias: {:.2f}\n'.format(ref_df['CV_MB_BIAS'].median())
scores += 'Mean bias: {:.2f}\n'.format(ref_df['CV_MB_BIAS'].mean())
scores += 'RMS: {:.2f}\n'.format(np.sqrt(np.mean(ref_df['CV_MB_BIAS']**2)))
scores += 'Sigma bias: {:.2f}\n'.format(np.mean(ref_df['CV_MB_SIGMA_BIAS']))
# Output
print(scores)
fn = os.path.join(WORKING_DIR, 'scores.txt')
with open(fn, 'w') as f:
f.write(scores)
This should generate an output similar to:
Median bias: 18.78
Mean bias: 15.34
RMS: 518.83
Sigma bias: 0.87
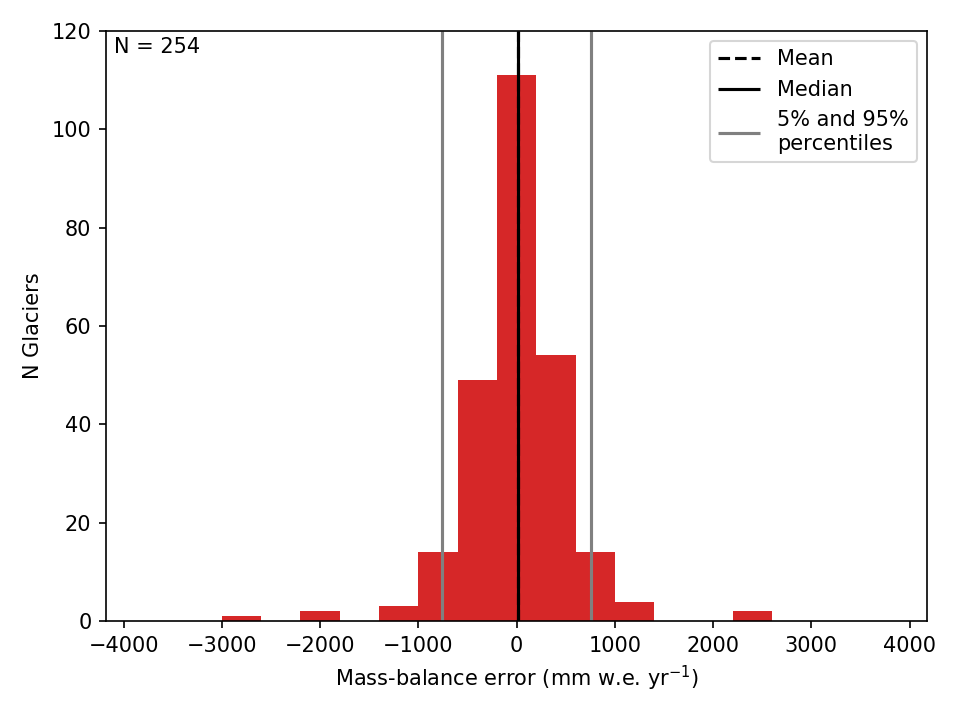
Error (bias) distribution of the mass-balance computed with a leave-one-out cross-validation.¶